AI-Assisted Discovery of SQL Injection & Stored XSS in Cacti Network Monitor
Disclosure status: Both vulnerabilities reported to vendor on 2026-05-13 via GitHub Pull Request.
Author: Nguyen Cong Tu (iaohkut)
Published: May 2026
I. Introduction
This post is about a methodology, not just a result.
Two weeks ago I found two vulnerabilities in Cacti — a widely-deployed open-source network monitoring platform used by operations teams worldwide. Both vulnerabilities have been reported to the vendor and are pending CVE assignment. I won't publish full technical details until a patch is available, but I want to write about what mattered most in this research: how I used AI as a code auditing partner, and what that actually looks like in practice.
This is a codebase of such a large size (~1,600 PHP and JavaScript files). I wouldn't have been able to do this at this speed without the help of Claude AI. This article details the workflow, suggestions, and reasoning process—so you can apply it to your own goals.
II. Target Selection
Why Cacti?
I chose Cacti for a combination of structural and strategic reasons:
Structurally interesting: Cacti is a PHP web application that wraps PHP's standard I/O functions in its own helper function layer.
High real-world impact: Cacti holds SNMP credentials, device access strings, password hashes, and session tokens for every monitored device. A vulnerability here doesn't just affect the web application — it's a pivot point into the monitored network infrastructure.
Active development with a long history: The CHANGELOG reveals that XSS and injection bugs have appeared and been patched multiple times over the years. This is a signal: the developers know about the pattern but haven't fully eliminated it. Variants are likely to exist.
Practical setup: Cacti ships with a docker-compose.yml. I could have a fully functional local instance running in under an hour, which is necessary for dynamic verification.
Environment Setup
The first session was entirely about infrastructure. I asked Claude to guide me through building Cacti locally from source:
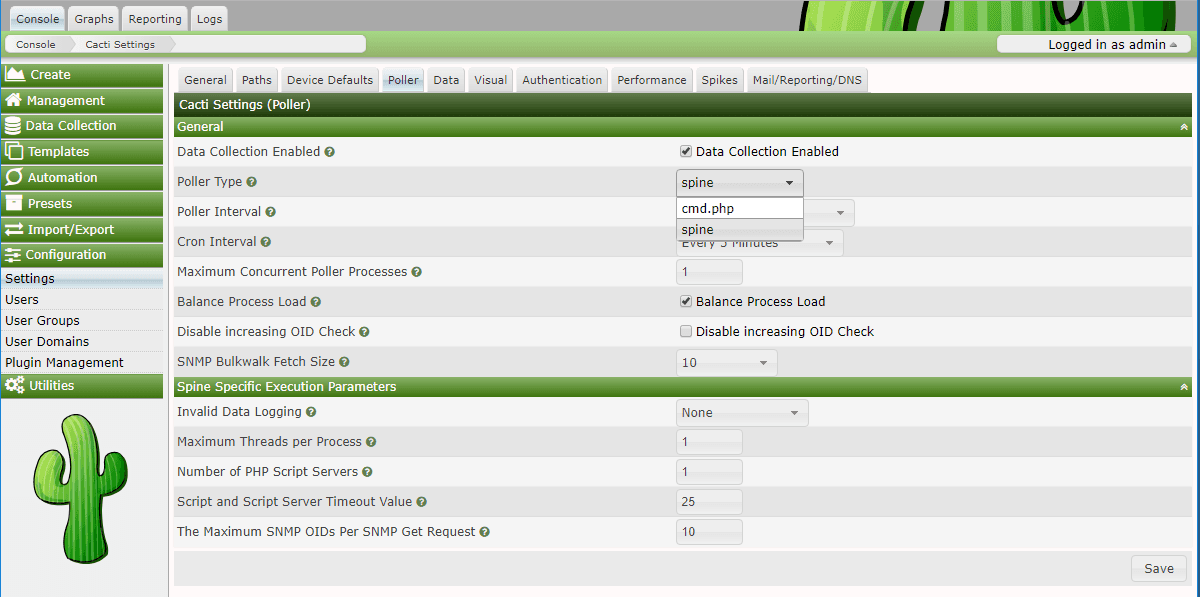
"From this GitHub open source for Project Cacti, could you help me build it on a local server as a lab exercise?"
Claude read the docker-compose.yml and Dockerfile, identified that the project uses an Apache + PHP 8.4 + MariaDB stack, and produced a step-by-step setup guide. Within 5-10 minutes I had a healthy instance at http://localhost:8082/cacti with credentials admin/admin.
Lesson: Using artificial intelligence (AI) to set up a research environment is highly valued because it only requires a simple prompt. It reads Dockerfiles and error logs faster than you can.
III. The AI-Assisted Audit Workflow
System Prompt: CLAUDE.md
Before any code analysis, I set up a CLAUDE.md file in my research workspace. This file acts as a persistent system prompt that configures Claude's behavior for every session:
Role: Expert vulnerability researcher and security mentor
Target type: PHP web application (techstack)
Method: Static analysis only
Goal: Find vulnerabilities suitable for responsible disclosure
Startup routine:
1. Map the codebase (languages, file counts, architecture)
2. Run applicable automated scanners
3. Prioritize findings by exploitability
4. Explain each finding: source → sink → impact → fix
Vulnerability explanation format:
- File & Line
- Code snippet
- Why it's vulnerable
- Attack scenario
- Impact
- CVSS estimate
- Fix
- CWE
This setup means I don't repeat instructions every session. Claude knows its role, its output format, and its priorities from the start.
Phase 1 — Codebase Mapping
I started the research session with a structured kickoff prompt:
Start a CVE research session.
Here is the target info:
Project: cacti
Source: https://github.com/Cacti/cacti
Version: v1.2.30 (lastest version)
Language: PHP / JS / ...
Goal: Find vulnerabilities suitable for responsible disclosure.
Follow CLAUDE.md workflow: run startup routine, run automated scans, prioritize by exploitability, explain each finding.
Claude's startup routine output:
📁 Languages : PHP (1,237 files), JavaScript (342 files)
🏗️ Architecture : Web application (monolith), PHP/MySQL stack
⚠️ Hot spots : AJAX endpoints without integer validation,
support.php unescaped output
🎯 Start here : data_sources.php, data_debug.php, support.php
The hot spots were flagged from the initial grep pass over dangerous function patterns. This took about 90 seconds.
Phase 2 — Automated Scanning and Triage
Claude ran Semgrep with the p/php ruleset against the source directory and returned a ranked list of findings. The key insight here is what Claude did after the scan: it didn't just dump the Semgrep output — it triaged.
Several findings initially looked promising but turned out to be false positives after Claude traced the validation flow:
templates_export.php—gnrv()used on a variable that had already been validated bygfrv()three lines earlier and stored in$_CACTI_REQUEST--> False positive.package_import.php— reflected output in an HTML attribute, butgfrv()had validated the value at line 104 before the output at line 385 --> False positive.cdef.php— potential JavaScript injection, but lines 113–118 validate the relevant parameter before the output path --> False positive.utilities.php—ORDER BYinjection candidate withgrv()direct concat, butCactiTableFilter::render()callssanitize_filter_variables()before any render — which promotesgrv()values to validated equivalents --> False positive.
Each dismissal took one or two follow-up prompts to verify. The process looked like:
"Check whether
CactiTableFilter::render()callssanitize()before the ORDER BY clause is constructed."
Claude reads the render method, finds the call to sanitize_filter_variables(), and confirms: safe. This back-and-forth is exactly how a senior engineer would triage a finding — and it meant I wasn't wasting time on non-issues.
Phase 3 — Identifying the Vulnerability Pattern
After triage, the remaining candidates pointed at a consistent pattern: AJAX endpoints that bypass the CactiTableFilter sanitization pipeline.
Here is the prompt that crystallised Finding #1:
"In Cacti,
gfrv()is the integer-safe version ofgrv()— it usesFILTER_VALIDATE_INT. Search for every place where a parameter that should be an integer (likesite_id,host_id,host_template_id) is read withgrv()instead ofgfrv(). Cross-reference those locations with any SQL query that uses the value. For each case, explain why PHP's loose typing could make the guard check bypassable."
Claude's analysis surfaced three AJAX action handlers across data_sources.php, data_debug.php, and reports.php. In each case, the same structure appeared: a numeric parameter is read with grv() (raw), a guard check of the form if (grv('param') > 0) is performed, and the raw value is concatenated into a SQL query.
Claude's explanation of why the guard fails:
"PHP's loose comparison coerces
"1 AND payload"to the integer1when compared with> 0. The check evaluates as1 > 0 = true, so the guard passes, and the string"1 AND payload"is concatenated verbatim into the SQL WHERE clause."
This is PHP type juggling — a well-known language behaviour that creates subtle logic bypasses. What made this discoverable by Claude was the combination of: (a) knowing the semantic difference between grv() and gfrv(), (b) spotting that AJAX paths skip the sanitization pipeline that would otherwise promote the value, and (c) understanding that the numeric guard check is bypassable via type coercion.
For Finding #2, the prompt was:
"In
support.php, find every place where a database-sourceddescriptionfield is printed to HTML. For each output site, check whetherhtmle()is called. If any block is missinghtmle()while a neighbouring block in the same file uses it correctly, that is a stored XSS — show me the diff."
Claude returned a diff showing two adjacent code blocks with identical structure. One calls htmle() on the description; the other does not. This is a copy-paste inconsistency — the kind of bug that is trivially easy to introduce and almost impossible to catch in a standard code review without systematically auditing every output site.
IV. Findings Summary
Full technical details, PoC payloads, and exact file/line references will be disclosed after the vendor releases a patch.
Finding #1 — Authenticated SQL Injection
Type: SQL Injection (CWE-89)
Severity: High — CVSS 8.8
Affected component: Multiple AJAX endpoints handling a numeric filter parameter
Root cause: Use of a raw input function instead of an integer-validated equivalent, combined with PHP's loose type coercion bypassing the numeric guard check
Who can exploit it: Any authenticated user with the lowest standard privilege level
What an attacker can achieve: Full read access to the Cacti database — including password hashes, SNMP credentials for all monitored devices, and persistent session tokens
Finding #2 — Stored Cross-Site Scripting
Type: Stored XSS (CWE-79)
Severity: High — CVSS 8.0
Affected component: A specific table block in the Technical Support page
Root cause: A missing HTML encoding call on a
descriptionfield output, while an identical adjacent block in the same file applies encoding correctlyWho can exploit it: Any authenticated user with the lowest standard privilege level (writes the payload); requires an administrator to visit a specific page (triggers it)
What an attacker can achieve: Administrator session hijacking → full privilege escalation → access to all infrastructure credentials stored in Cacti
V. Dynamic Verification
Finding a vulnerability in source code is only half the work. Before reporting anything, I verified both findings on the live local instance.
Verifying Finding #1
The verification technique I used is boolean-based differential analysis — a method that doesn't require time delays or error messages. The idea is:
Send a request with a TRUE injected condition → observe the response
Send a request with a FALSE injected condition → observe the response
If the responses differ in a meaningful way (e.g., number of records returned), the injection is real
Claude designed the test, explained why each payload would produce the expected result, and flagged a subtle point: SQL comment syntax (-- ) doesn't work cleanly in URL-encoded query strings in this context — I needed to use bare AND condition without comments, because the injected clause is appended before the WHERE wrapper closes. This kind of implementation detail is where AI earns its keep.
The verification was confirmed within minutes. A follow-up subquery payload extracted the first character of the administrator password hash, confirming full data extraction capability.
Verifying Finding #2
For the XSS, I created a test device with a JavaScript payload in the description field, then triggered high poll failure rates via a direct database update (to force the device to the top of the worst-ratio list). I then fetched the affected page source and looked for the two adjacent HTML blocks — one that should escape the payload and one that shouldn't.
Claude helped interpret the HTML diff:
"The page source contains both blocks for the same device. Block 1 (polling times) shows the payload HTML-encoded. Block 2 (poll failure ratio) shows the payload raw and unescaped. This confirms the finding: the encoding is applied in one context but not the other."
The screenshot below shows the JavaScript payload executing in the administrator's browser, displaying the session cookie:

The payload fires on the Technical Support page when viewed by an administrator. The session token is visible in the dialog.
VI. What AI Did — and Didn't Do
What Claude contributed
| Task | AI contribution |
|---|---|
| Environment setup | Read Dockerfiles, diagnosed port conflicts, generated setup guide |
| Codebase mapping | File enumeration, language breakdown, hot-spot identification |
| Automated scan triage | Traced validation flows for false positive dismissal |
| Pattern identification | Connected grv() vs gfrv() semantics to bypass via PHP type juggling |
| Output encoding audit | Compared adjacent code blocks, found the missing htmle() |
| Verification design | Designed the boolean-based test, flagged the comment-syntax pitfall |
| Report drafting | Structured CVE report drafts with CVSS vectors, CWE references, fix examples |
What I contributed
Choosing the target and understanding why Cacti was worth auditing
Formulating the prompts — the right question is 80% of the work
Judgment calls on which leads to pursue vs. deprioritize
Dynamic verification — running the actual action on Browsers and interpreting the results
Responsible disclosure — knowing when and how to report, what to include, and who to contact
Claude is not an autonomous vulnerability scanner. It is an extremely capable reasoning partner that can read code, trace data flows, and identify semantic inconsistencies — but only when you give it well-structured questions and real source code to work with.
VII. Prompting Lessons
After two research sessions, here are the prompting patterns that worked:
1. Define semantic contracts, then find violations
Don't ask: "Is there SQL injection in this file?"
Ask: "Function X is the safe version of function Y. Find every place where Y is used on a parameter that should be handled by X, and explain why."
This forces Claude to reason about the intended contract of the code, not just keyword-match dangerous patterns.
2. Ask Claude to explain its false positive dismissals
Don't just accept "this is safe." Ask:
"Show me the specific line where the validation happens and explain exactly why it prevents exploitation."
This keeps you honest and sometimes reveals that the validation is narrower than it appears.
3. Use comparison prompts for output encoding
Instead of "find XSS in this file," ask:
"Find every place where field X is output to HTML. For each output site, tell me whether encoding is applied. If some apply it and others don't, show me the diff."
Comparison prompts surface inconsistencies better than single-focus scans.
4. Design verification tests with AI before running them
Before sending any test request, ask Claude to:
Predict what the TRUE response will look like
Predict what the FALSE response will look like
Flag any implementation pitfalls (encoding issues, syntax constraints, etc.)
This saves you from running invalid tests and misinterpreting the results.
VIII. Responsible Disclosure
Both findings were reported to the Cacti project via a GitHub pull request on May 13, 2026, and have been merged into their repositories by the authors.
IX. Closing Thoughts
The most important skill I developed in this research wasn't vulnerability analysis — it was prompt engineering for code auditing. Knowing how to ask Claude to compare semantic contracts, trace validation flows, and design differential verification tests is a genuinely transferable skill that applies to any codebase in any language.
AI doesn't replace the judgment needed to choose targets, interpret ambiguous results, or navigate responsible disclosure. But it dramatically reduces the time between "I have source code" and "I have a confirmed finding" — especially for beginners who are still building their intuition for what dangerous patterns look like in unfamiliar codebases.
I'll publish a full technical follow-up after the patch is released, including the exact vulnerable code, PoC payloads, and CVSS vector breakdown.

![[CVE-2026-48731] AI-Assisted Discovery of Command Injection in Warp Terminal](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fuploads%2Fcovers%2F699fec8cc9015c37f6e5364f%2Fe7817cef-a8af-45ec-b931-4e08225edeb6.png&w=3840&q=75)